
Evaluating an OmniParser-Based Data Pipeline for Structured Extraction from Steam Review Screenshots
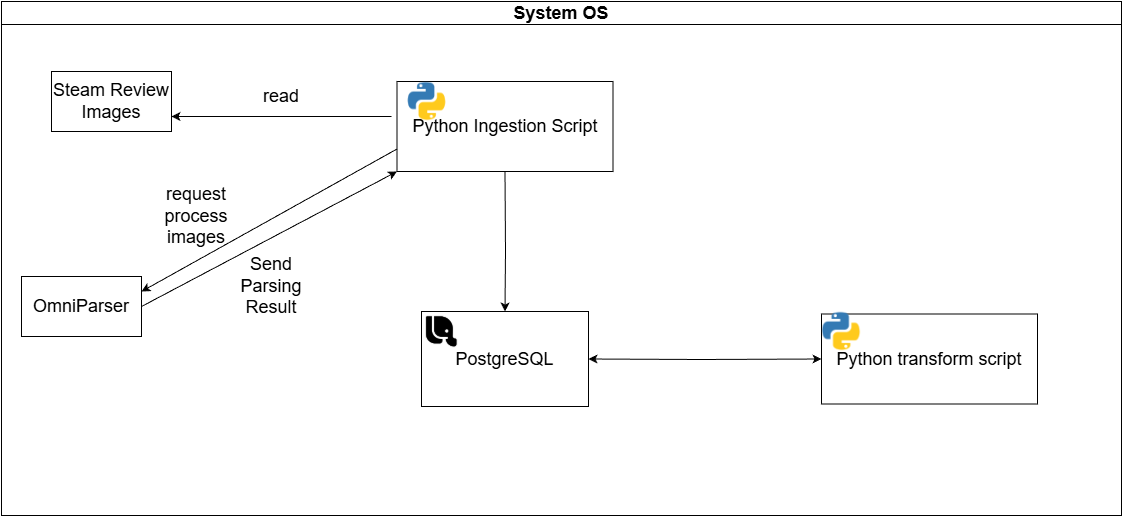
This project evaluates whether OmniParser can be used as the data extraction component of a data pipeline for capturing Steam review information from screenshots and converting the parsed output into structured records. The evaluation is conducted along three dimensions: extraction accuracy, data completeness, and operational reliability. Extraction accuracy measures how correctly the extracted values match the expected review data. Data completeness checks how many extracted reviews can be reconstructed and matched to the corresponding Steam Review API records. Operational reliability examines whether OmniParser can process batches of Steam review screenshots consistently and stably under the tested conditions. To support the evaluation, two data pipelines are implemented. The first is an Omni Parser-based pipeline used for the experiment evaluation. The second is called the Steam Web API-based pipeline, which provides the ground truth review data for value comparison. The results show that the OmniParser-based pipeline achieves high extraction accuracy for several short, structured review metadata fields, but performs poorly on free-text review extraction. The pipeline also shows operational instability under OmniParser cold start conditions, especially when processing long, text-heavy screenshots. Overall, the findings suggest that the current OmniParser-based approach is not suitable for reliable real world usage for ingesting and transforming Steam reviews.