
Training-Time Safety Dynamics for Constrained Reinforcement Learning in Safety-Gymnasium
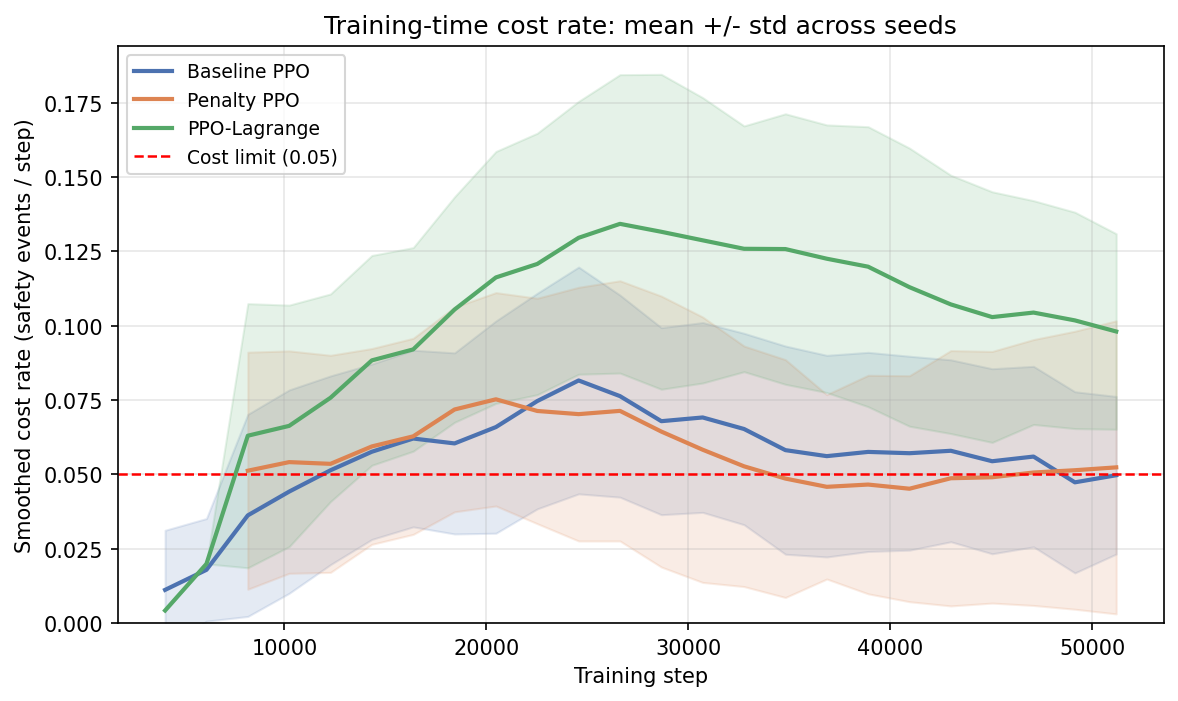
Abstract Reinforcement learning methods are often evaluated using final average performance measures such as reward and cost rate. In constrained reinforcement learning, however, such summaries may not fully describe how unsafe behaviour appears during training. This project investigates whether final average cost is sufficient to characterize safety or whether additional training-time diagnostics lead to materially different conclusions about algorithm behaviour. Using the SafetyPointGoal1-v0 environment in Safety-Gymnasium, three methods were compared under a shared experimental setup: unconstrained PPO, fixed cost-penalty PPO, and PPO-Lagrange. In addition to final evaluation metrics, the project measured training-time peak cost rate, volatility, tail-risk summaries, time-to-feasible, unsafe streak persistence, and ranking disagreement across metrics. Under the main fixed-budget comparison, Penalty PPO achieved the strongest safety improvements under final evaluation, but at a statistically significant reward cost. PPO-Lagrange preserved reward relative to the baseline but remained close to baseline on final safety and showed worse peak and tail-risk behaviour during training. An exploratory longer-horizon follow-up for PPO-Lagrange further suggested that training budget was an important factor, although this did not replace the main shared-budget comparison. Overall, the results support the project hypothesis that final average cost alone is insufficient to characterize safety during learning, as different metrics can yield different comparative conclusions.