
Multi-Stream Spatiotemporal Video Transformer for Automated Cataract Surgical Phase Recognition: A Cross-Institution Validation Study
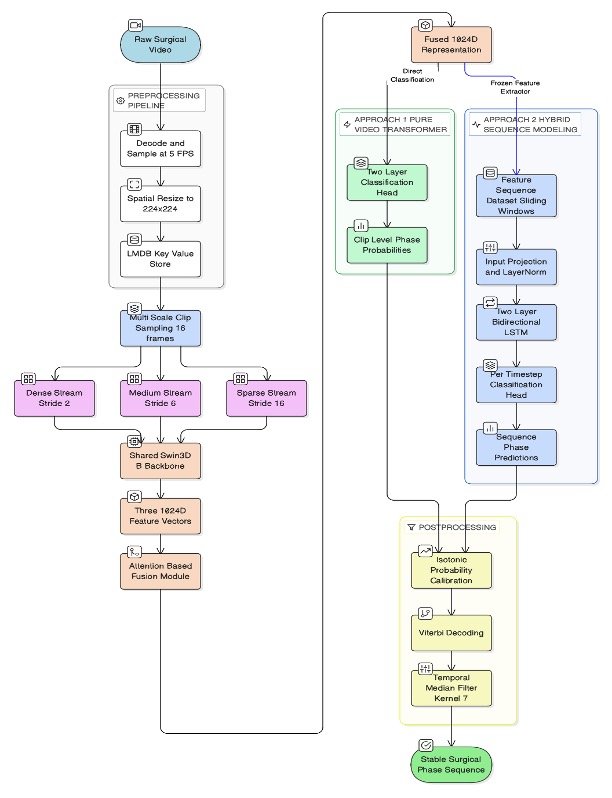
Cataract surgery is among the most frequently performed ophthalmic procedures, yet the supply of trained ophthalmologists continues to fall short of global demand. Automated workflow analysis through video input holds considerable promise for scaling resident training through objective, phase-specific feedback, but progress has been limited by three persistent gaps. This includes reliance on manually pre-segmented video inputs, poor cross-institution generalization, and training datasets which underrepresent resident-level variability. This thesis proposes and evaluates two spatiotemporal deep learning architectures to tackle all three limitations simultaneously. The first architecture involves a triple-stream Video Swin Transformer (Swin3D-B) that processes dense, medium, and sparse temporal clips of full-length surgical videos in parallel, fusing their representation using a learned attention module. To add inter-clip temporal context, the second architecture extends this backbone with a Bidirectional LSTM (Bi-LSTM) to model sequential phase dependencies across an entire surgery. Both Swin3D and Swin3D+Bi-LSTM models are trained using a 209-video annotated dataset from the Kingston Health Science Centre comprising both faculty and resident surgeons and externally validated on the publicly available Cataract-101 dataset from the University of Klagenfurt, Austria. On in-domain internal data, both the Swin3D and Swin3D+Bi-LSTM hybrid models achieved mean accuracy of 94.02% and 94.04% respectively, with Jaccard indices near 0.84 on continuous unsegmented video inputs. Testing both models on out-domain external data revealed notable domain shift (Swin3D: 59.26%, Swin3D+Bi-LSTM: 56.04%). This was however largely recovered through fine-tuning on a single surgeon’s data from the external target institution (Swin3D: 88.09%, Swin3D+Bi-LSTM: 88.79% accuracy) which demonstrated a practical low-annotation deployment pathway. Following ablation studies on the sampling stream setups, results confirm that combining dense and sparse streams drives most of the performance gain. Ultimately, these results position the proposed framework as a foundation for future promising multi-domain phase-specific skills assessment.